



Problem
You have a service that has a dynamic load of incoming traffic to perform heavy-weight operations. Luckily, the client doesn't demand an immediate response from our service.
If possible, we still need to deliver the result fast enough, because the client doesn't want to wait any longer.
Solution
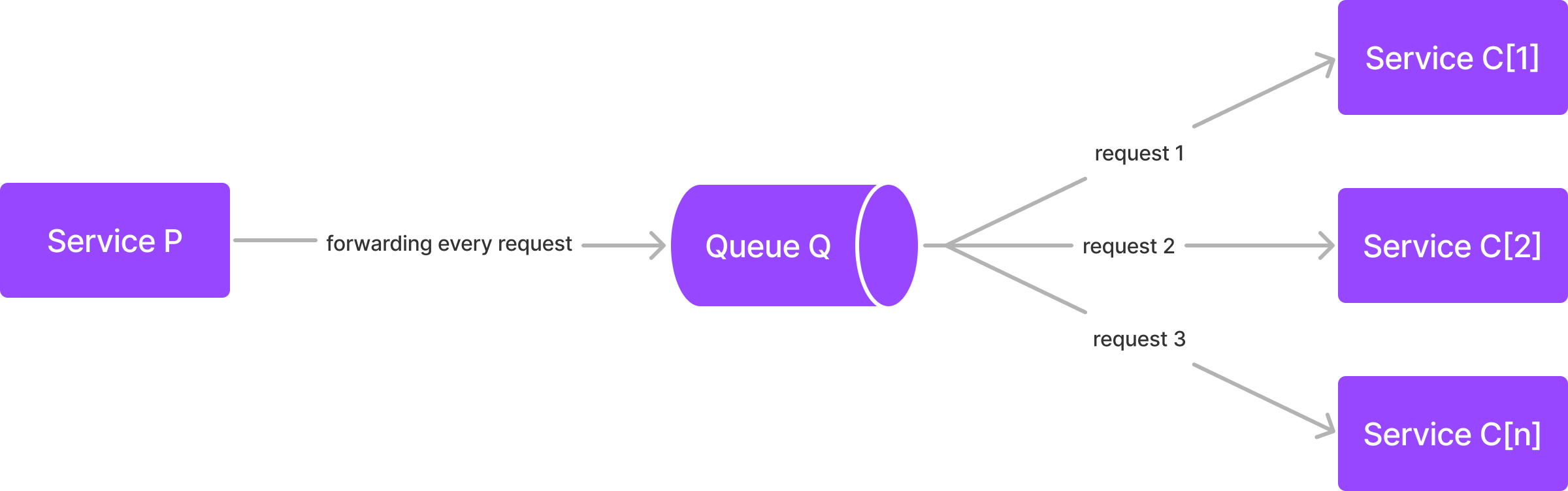
Let's say we have a service named P, which always receives operation requests from clients.
Service P will forward any requests to a queue named Q. Every time service P successfully forward the request, the client needs to wait for the result of the operation.

On the other side, there is n number of service C. Every service C[i] will consume any possible request from queue Q.
Normal Case
Under the hood of queue Q and every n of service C, you will notice for every request will only be processed by one of any possible service C. This is a very important remark that becomes what a message queue is.
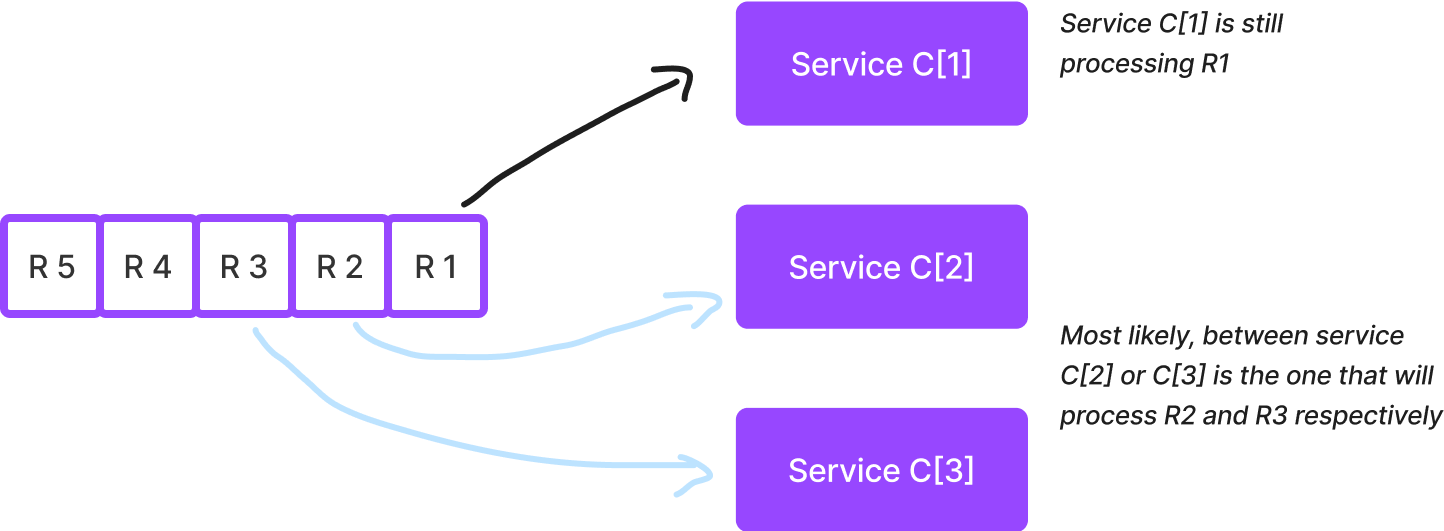
After a service has begun processing a request, the next request is available for processing for any available service C. But that request is not effectively gone from the queue Q.
Service C shall give an indication, of whether it needs to be ACK (success and ok to delete) or NACK (error and no for delete). When that request is given an ACK command, we won't have a further issue.
Handling NACK
NACK is used as an indication that the operation of the request is failed. Retry would do, and we can give it a try. But we need to set some limits on that.
Simply just re-queue
Re-queue and track
Send to dead letter queue
Simply just re-queue a request. This is typicaly of what service C will do. Hoping the next service C that will process this request will do just fine. If there are n number of service C and there are n-1 needed to be requeued, there is at least one service C that will process the remaining request. It means the queue still moves on.
Re-queue and track how long it has been re-queued. We may need to give special treatment after some retrying.
Send to the dead letter queue would be the best option to send this problematic request to the dedicated queue of problematic requests. We might need to take a look at this queue later manually.
References: